In this blog I want to show you the design process that went into creating the “Top Contributor Network” visual. Showing the ecosystem and synergy of the other repositories the top contributors of any GitHub repository have worked on.
How it started from a simple network, and became it’s own thing. How it involved endless tweaking, and how it then all broke, before growing into its final form.
You can find the interactive visual here (ps: it’s not really meant for mobile screens) and you can find all of the code and documentation for the visual here.
How it Got Started
In January of 2023, Adam Bouhenguel reached out to me. He is part of Mozilla’s MIECO Program that funds innovators to build a healthier internet experience. He was ready to put ORCA out into the world, the Open Retrospective Compensation Agreement. Where business share a part of their revenue with the contributors of the open source projects they use.
The recipients of ORCA are free to decide what to do with the funds.
As part of launching the concept of ORCA, Adam was looking for several visualizations to reveal the potential impact that applying ORCA could have. If you share a part of your revenue with the (top) contributors of a certain open source project that is vital for your business, the hope would be that this gives those people the time to make further improvements and do maintenance. However, many of these people usually also contribute to other open source projects. Your compensation could therefore reach even farther. Meaning that the other open source projects also indirectly benefit (and perhaps some of those are also important to your business).
The Concept
The exact definition of “top” or “impactful” is left to be defined by those who want to apply ORCA.
It was clear that the first visual should focus on the people, the contributors to the open source project, specifically on GitHub. It would have to be able to show the top / most impactful contributors of any GitHub repository, and reveal what other repositories these people had worked on. To see how any ORCA contribution to these people could have an indirect impact on the work they do on other repositories as well.
It should be a visual that can be applied to any GitHub repository that has at least some contributors (as long as the data is prepared correctly). It didn’t have to be a 100% can-handle-anything kind of visual, but a pretty darn good prototype that should work for most. Hopefully, this would spark some people that are better in the technical side than I am to perhaps develop it even further.
The Inspiration
During the many calls I had with Adam before truly starting, I had shared “the Oscars” visual from the New York Times as a point of inspiration. In it, actors and directors are connected through the movies that they have been involved in. For this new visual it would be contributors that would connect through their repositories; a network visual.
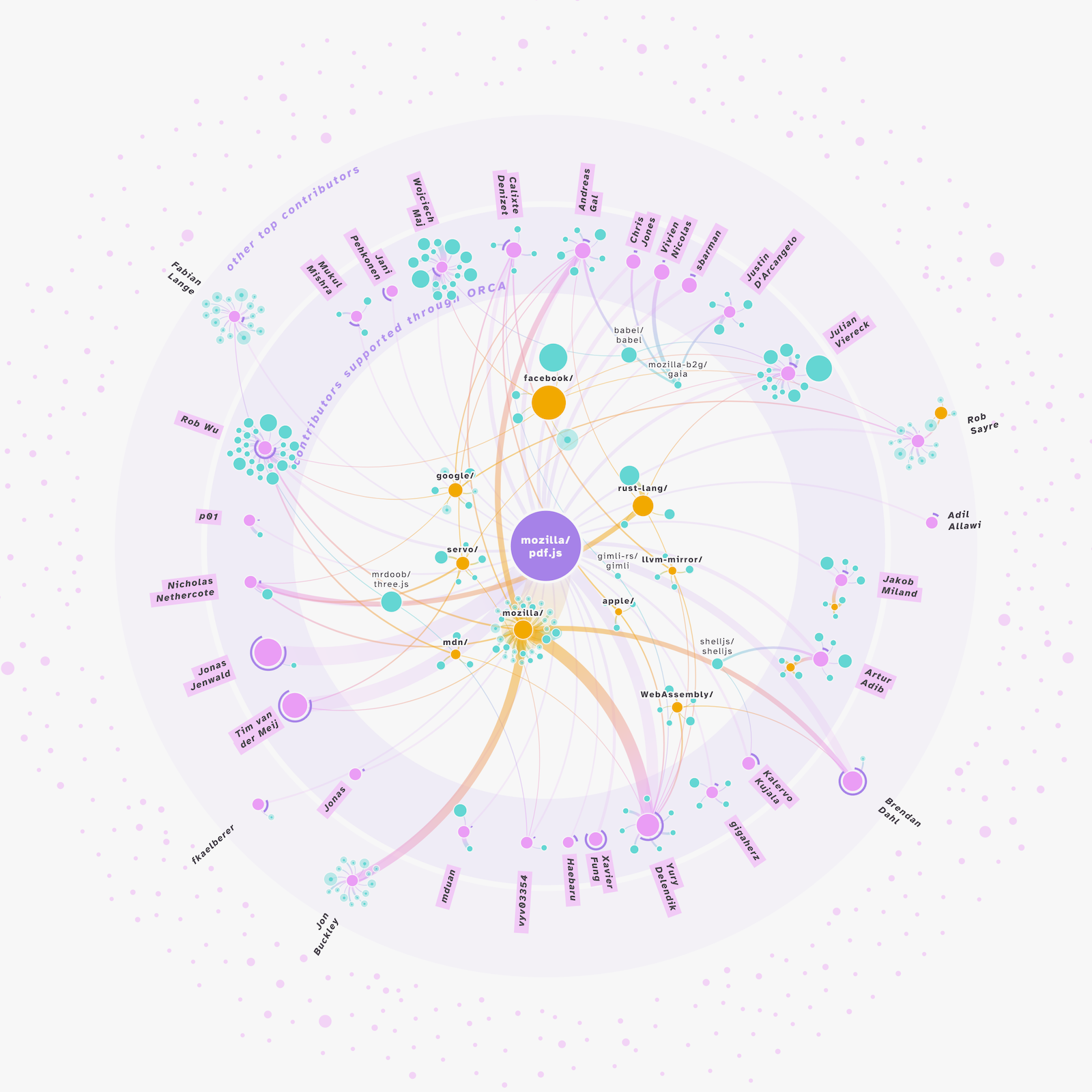
The Data
One of Mozilla’s GitHub repositories, pdf.js was chosen as a dataset to build the visual with. In general, the data required is straightforward. You need information about the “nodes”, or entities in the network, being the contributors and repositories here. And you want the “links”, the connections between the nodes.
I split the dataset of the nodes in two. First, a list of the “top contributors.” Being anyone that has made an impactful contribution to the repository. This is quite a vague concept and hard to define though. Eventually it will be up to each person wanting to use the final visual with their own dataset to determine what “impactful” means to them. For this visual/prototype, we decided to start simple and take it as the contributors with the most commits.
It is important to not include forks, but only repositories that a contributor directly made commits to.
Next, you want a list of all the repositories that these top contributors have made commits to. Together with some metadata about the repositories, such as their creation and latest commit date. However, to not overload the visual, and to only focus on repositories that have been deemed “useful” I decided to take a (somewhat) arbitrary cut-off point, and only include repositories that have at least 30 stars.
The third dataset would be the links between the contributors and the repositories. And again some metadata about these connections, such as the number of commits that a contributor made to a certain repository. Plus, the time between their first and most recent commit to the repository.

You can read more about the exact required schema on the GitHub Readme of the visual.
A side note | We didn’t quite get to the final data in such a linear fashion. It took a bit of back and forth, using a somewhat out of date dataset of contributors and the repositories they have worked on, combined with up-to-date information gotten from the GitHub GraphQL API about the contributors and repositories (through R). So the data in the visual prototype isn’t 100% correct, and might not include all repositories. However, for showing the concept of what this visual would be able to show, it was than enough.
Getting the Layout Right
Since this visual was a network at its core, I did what I always do with networks: get all of the data on the screen as fast as possible, using d3.js’ force simulation, and seeing how tangled it looked.
With contributors in black (all equally sized for now), and repositories in red (sized according to the number of stars), this is what appeared:
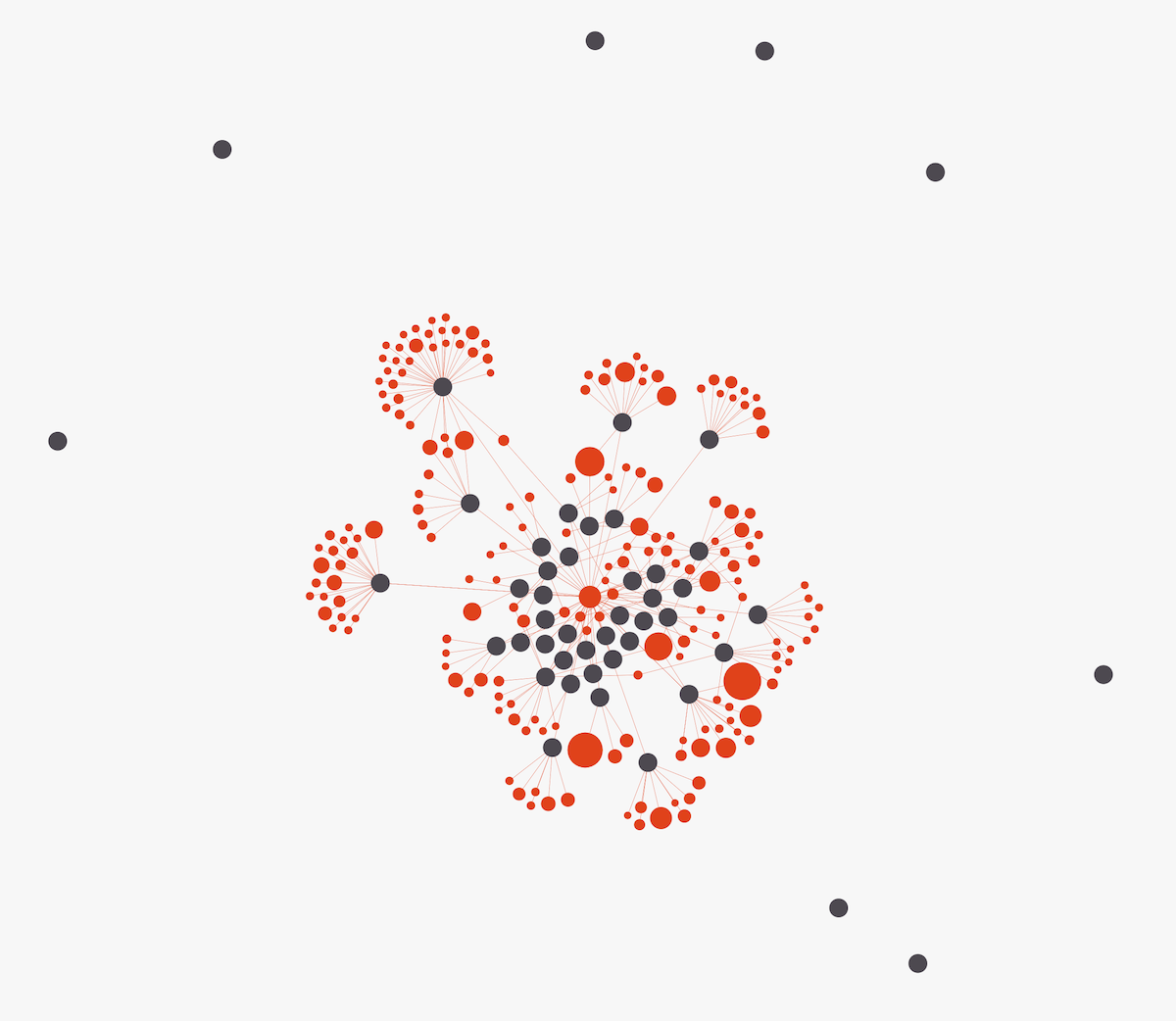
I am generally only okay with using a “pure network” like this when I know the dataset will never change, and thus I can tweak the network’s settings to be optimal for that particular dataset.
And, compared to the typical mess that I usually get when I first start out with network-related projects, this one was quite nice looking. No hairball at all! However, it didn’t seem like the best form to find insights from this network. I also knew that the final visual should have the potential to work for many GitHub repositories. And a pure network layout like this isn’t something you can rely on to work for each dataset. The “hairball” potential is quite high.
And so I needed to add visual constraints. Something that would fix the placement of some part of the network, making (pretty) sure you didn’t end up with hairballs. Something that would also make the network insightful, no matter what dataset you threw at it (well, almost).
Being able to pre-fix the positions of the thirty-something top contributors seemed like the best option to me. During the data preparation I had already noticed that most of the repositories were only connected to one contributor; only one person (from the top contributors of pdf.js) had made commits to it. Therefore, being able to fix the contributor nodes would also fix many of the repository nodes.
Apart from some contributors (eventually) being awarded with ORCA, we did not want to distinguish between the top contributors in any other way; they are all seen as valuable/impactful. And so, placing them in a ring around the “central repository”, all an equal distance from the center, made the most sense. With the central repository being pdf.js, the repository that they were the top contributors to.
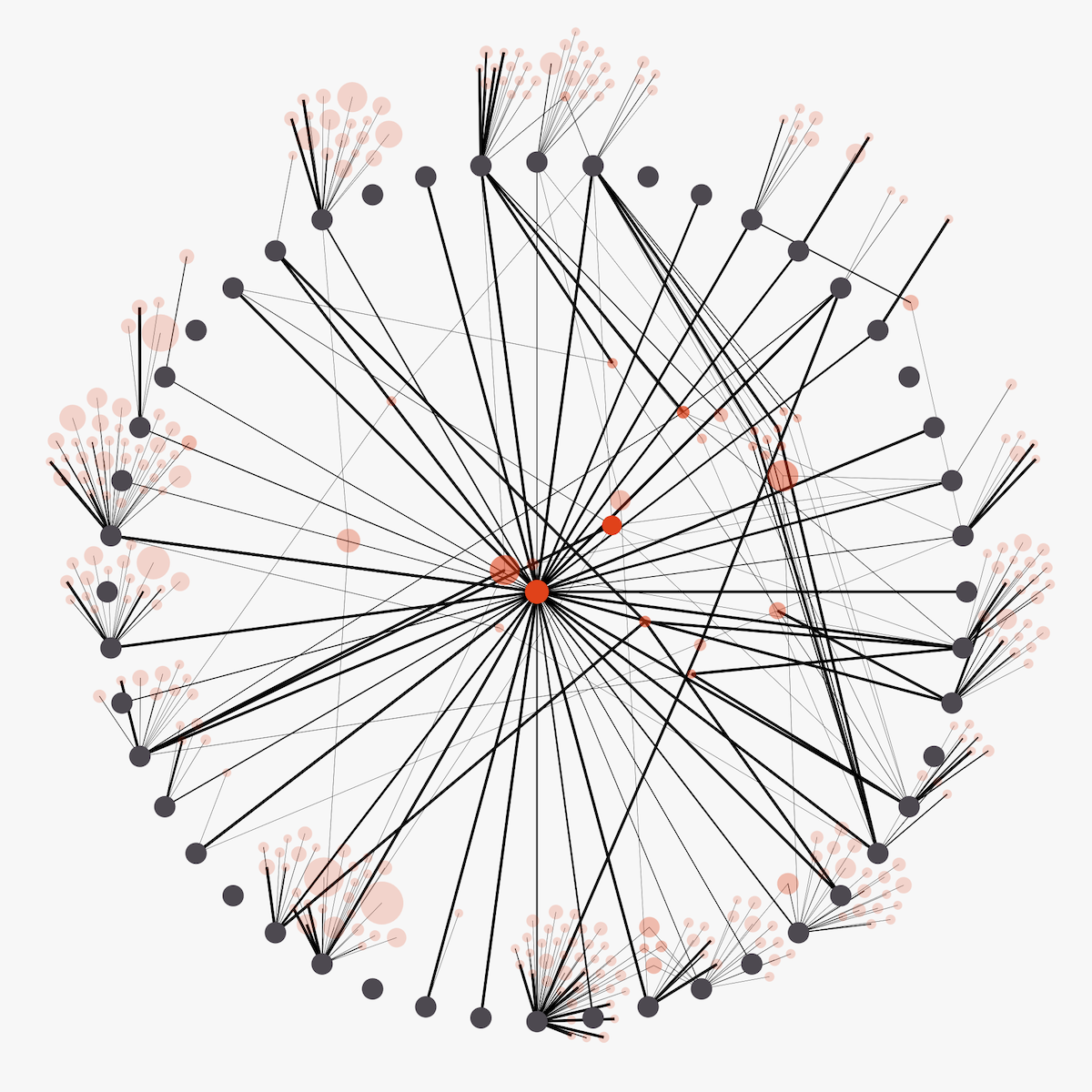
I’ll be referring to the “repositories only connected to one contributor” as “single-degree repositories” from now (single-degree meaning only 1 connection, 1 line).
I was definitely seeing the potential in that first result; the contributors are clearly separated, some with their flock of repositories that no other contributor has worked on, and those repositories with multiple contributors in the center. However, it required a lot of fine-tuning! For one, the red repository circles that were only connected to one contributor looked strange, with them being seemingly pushed away as a group.
Layering Force Layouts
Something that I’ve been doing more and more is to use multiple force layouts within one network. Sometimes side-by-side, sometimes in a hierarchical way. The latter is what I did here. I wanted those single-degree repository circles to be positioned nicely in a circle around their contributor, and not be affected by any other node in the full network. And so I looped over each contributor, picked out their single-degree repositories and ran a separate force-layout on this contributor and its repositories. Getting a bit “d3-technical:” fixing the contributor circle at 0,0 and with the non-collision being the only “force” acting on the repository circles, so that they would be nicely spaced out.
I forgot to take screenshots with the red-black color scheme, so here is one with the final colors that we’re switching too soon.
To check the results from this, I arbitrarily visualized them in a grid. Sometime during this process I started to scale the contributors by their number of commits to the central repository.

Next, I saved all of the relative positions of these repositories, calculated the placement of the contributors in a circle around the central repository, and put the repositories in their relative positions to their contributor. One more force algorithm was then needed for the positions of the remaining repositories that did have connections to multiple contributors (ending up in the central part of the visual).
There was still more fine-tuning needed, but I liked how it made the visual easier to explore and more insightful than that very first network.
Tweaking the Design
Yes, I know the ‘A’ in ORCA already stands for agreement, but I don’t expect every reader to remember that ;)
Feeling that I was on the right track with this layout, I looked into the design side. Adam had asked Julie Brunet, aka @datacitron to help with the design of the ORCA agreement itself. She’s made it look from a boring document to something professional and beautiful. And I used that as inspiration for this visual, as I felt it would be a bonus if they looked like they belonged together.

I made the blue a bit darker, the one in the agreement is a bit too light to use as a circle color.
I took the colors, made the contributors pink and the repositories turquoise. I wanted that “central repository” to stand out, and felt that a warm yellow would work well as a third color. I used the same font as the agreement (Atkinson Hyperlegible). I curved the lines running between all the circles, since I personally think that looks more elegant than straight ones, especially in a perfectly circular layout like this. And I added a color gradient to the lines.

Adding the lines that connect every contributor to the central repository (a bit more transparent than the other lines) and upping the line thickness (scaled by the number of commits from contributor A to repository X), and this is where it stood:
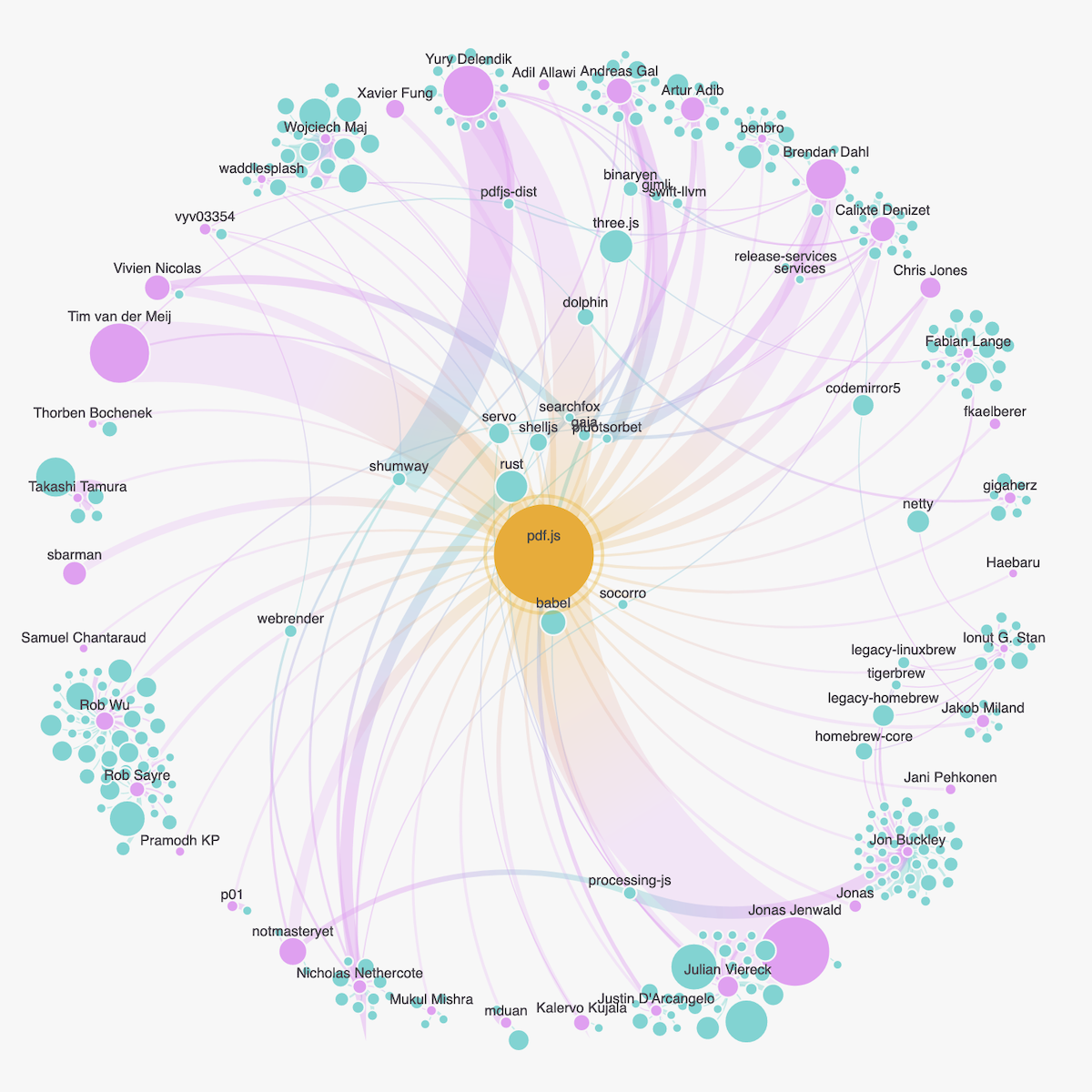
Fine-tuning the Contributor Placement
I’ll get to overlapping labels later.
The network itself needed more attention too, as some of the single-degree “clouds” of two contributors could overlap if they were big enough. See “Rob Wu” and “Rob Sayre” in the bottom-left of the previous image. The solution was a bit more math. It roughly comes down to:
- Calculate the radius of the smallest circle that can enclose the entire “cloud” of the contributor and its single-degree repositories. This becomes the “new” radius of the contributor to take into account for its placement.
- Define an amount of “padding” that you want between contributors.
- Loop over all contributors, adding up their diameter and the padding. At the end you’ll know the circumference of the circle that can fit all of the contributors, and thus the radius (
circumference = 2 * pi * R) - Loop over the contributors again, and using the radius (and padding), calculate the angle at which they should be placed around the central repository (remember the arc length formula:
arc length = θ * R)
Adding Smaller Details & Interactivity
I love adding small visual aspects into my visuals, the nice-to-have details of the data, as extra visual diversity and as extra context for the truly interested viewer. Adam suggested that I somehow add a marker that showed how long each contributor had been involved with pdf.js, the central repository. As a simple proxy for this, I can use the time between their first and last commit to the repository.
Since this represented time, I started to think of the circles as a representation of a clock. Where a full circle would represent the “existence time” of the central repository; the time between the creation of the central repository and its most recent commit, going clockwise. I added a small yellow arc around each contributor, starting along that circular timescale at the time of their first commit and running to the time of their most recent commit. The bigger the arc, the more time between their first and last commit.
Placing the arc within the circles didn’t look good…
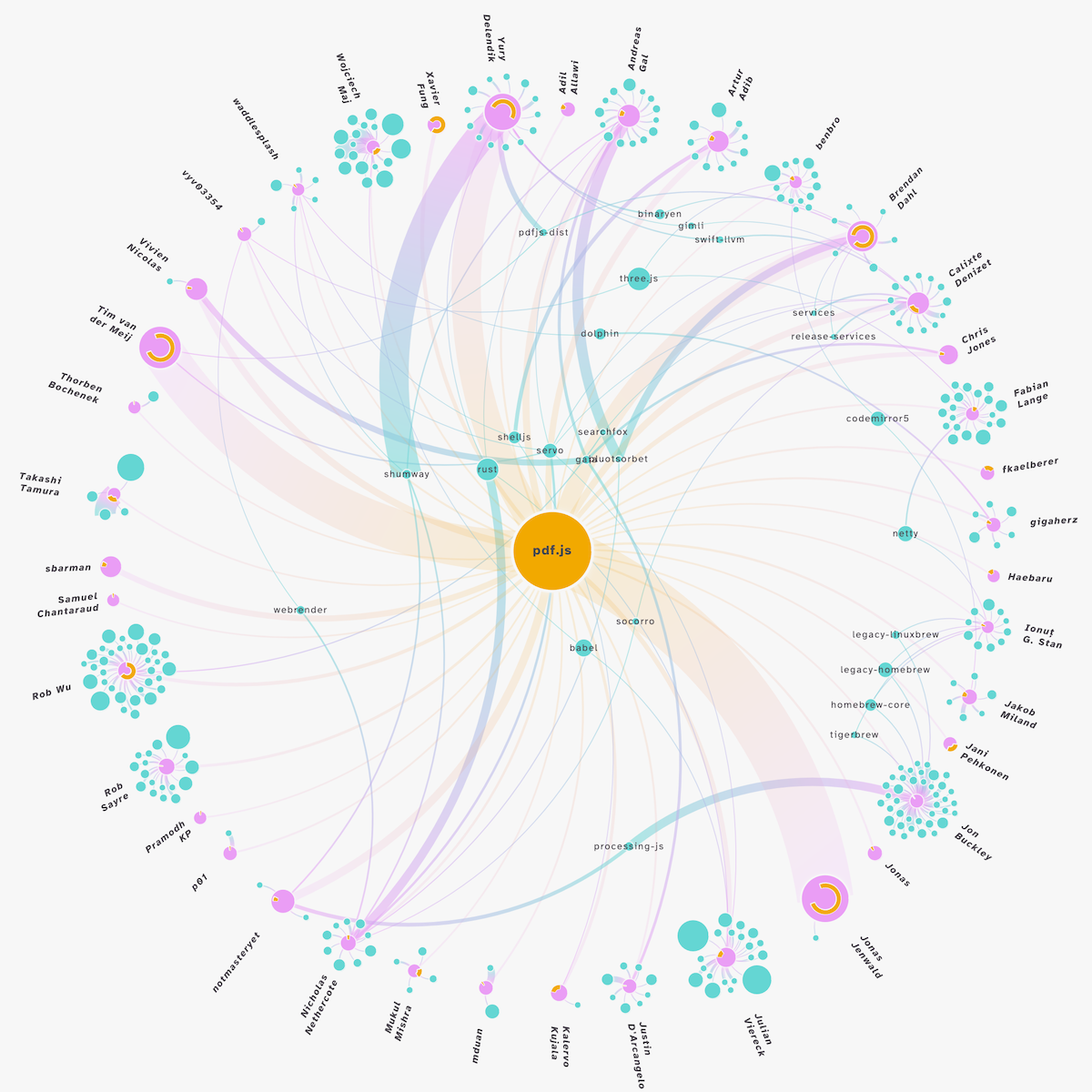
But just around the outside worked well with the design (see the next screenshot farther below). Also, another small change in the screenshot above; the contributor’s labels are no longer overlapping their possible little “cloud” of repos, but placed radiating away from the center.
Next up, some interaction. This being a network visual, on the internet, you almost have to have some basic hover interactivity going on. Hover over any circle and see all of its connections light up. As I was creating this visual with HTML5 Canvas, I incorporated some d3-delaunay that would help me find the closest circle to the mouse position and if a hit was found, dim the whole network and draw a fully opaque version of the hovered circle and its connections on top.
Here’s a test shot where I was trying to figure out why the hover interactivity wasn’t working as expected. Apparently the scaling between the visual elements and the (grey/black outlined) delaunay cells / triangulation was subtly off.
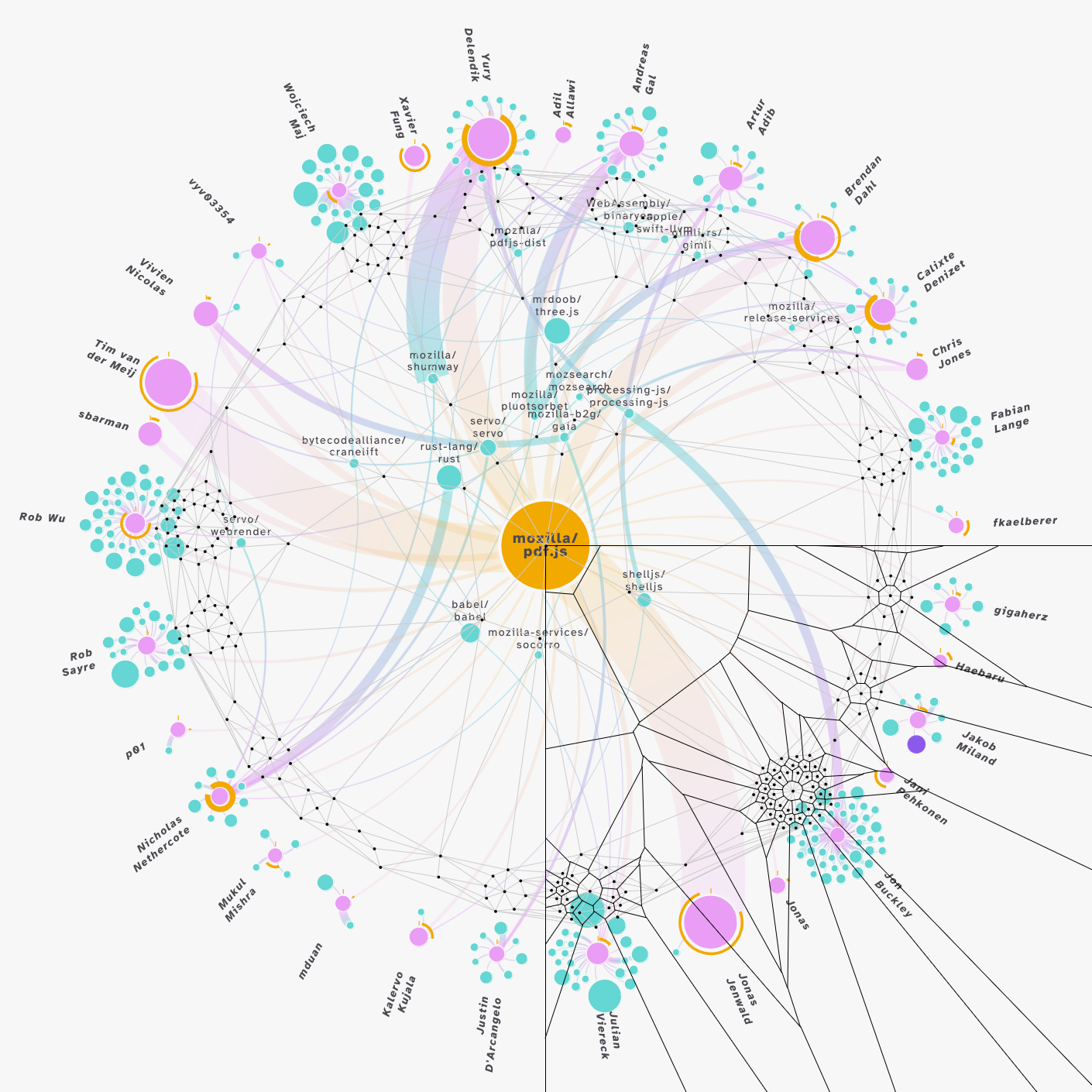
I built the tooltip in canvas, but in hind-sight really should’ve used a separate div
I built a tooltip that would give more metadata about the hovered node. Giving different information depending on the type of the node (e.g. contributor or repository), and depending on what metadata was available for that data point.
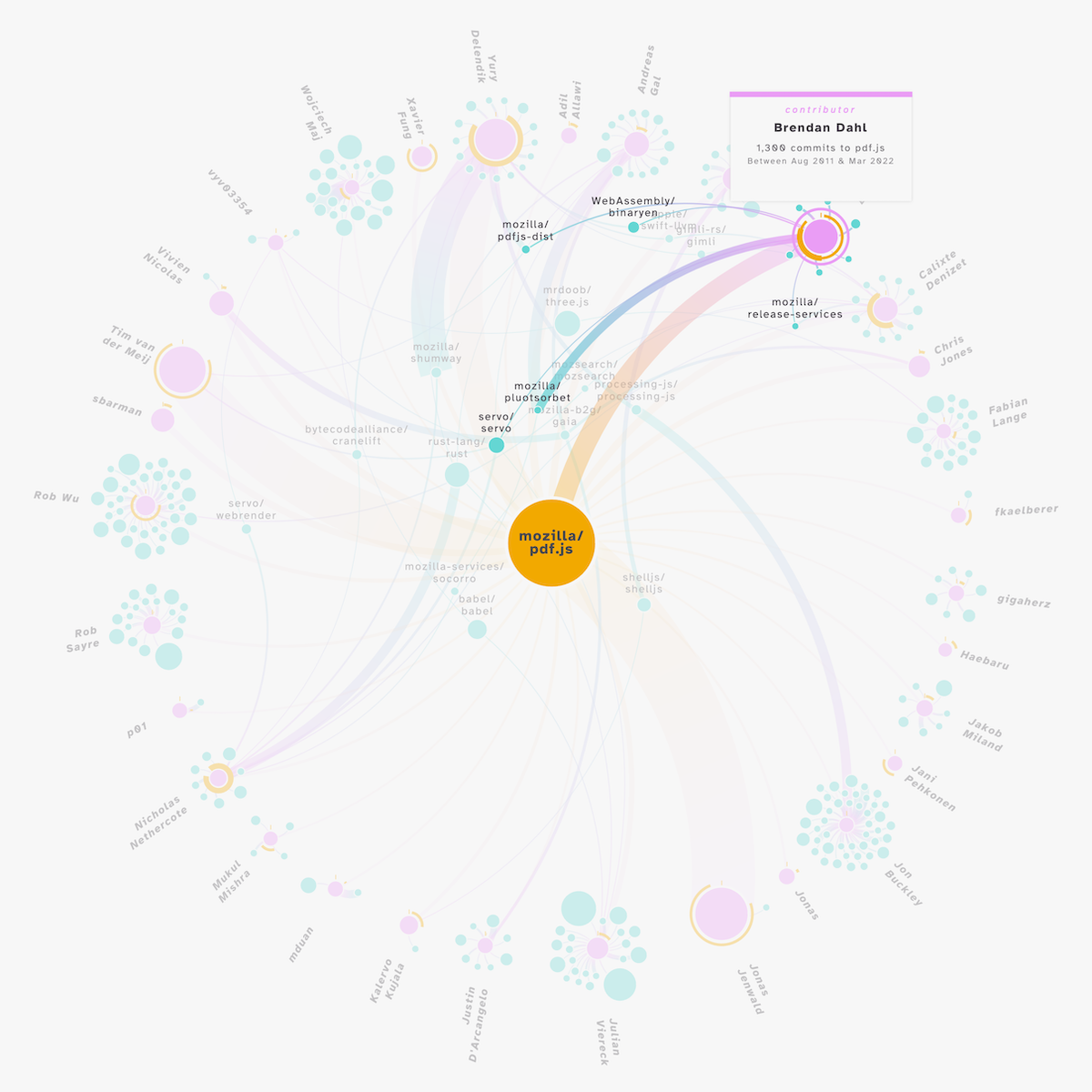
ORCA vs. non-ORCA
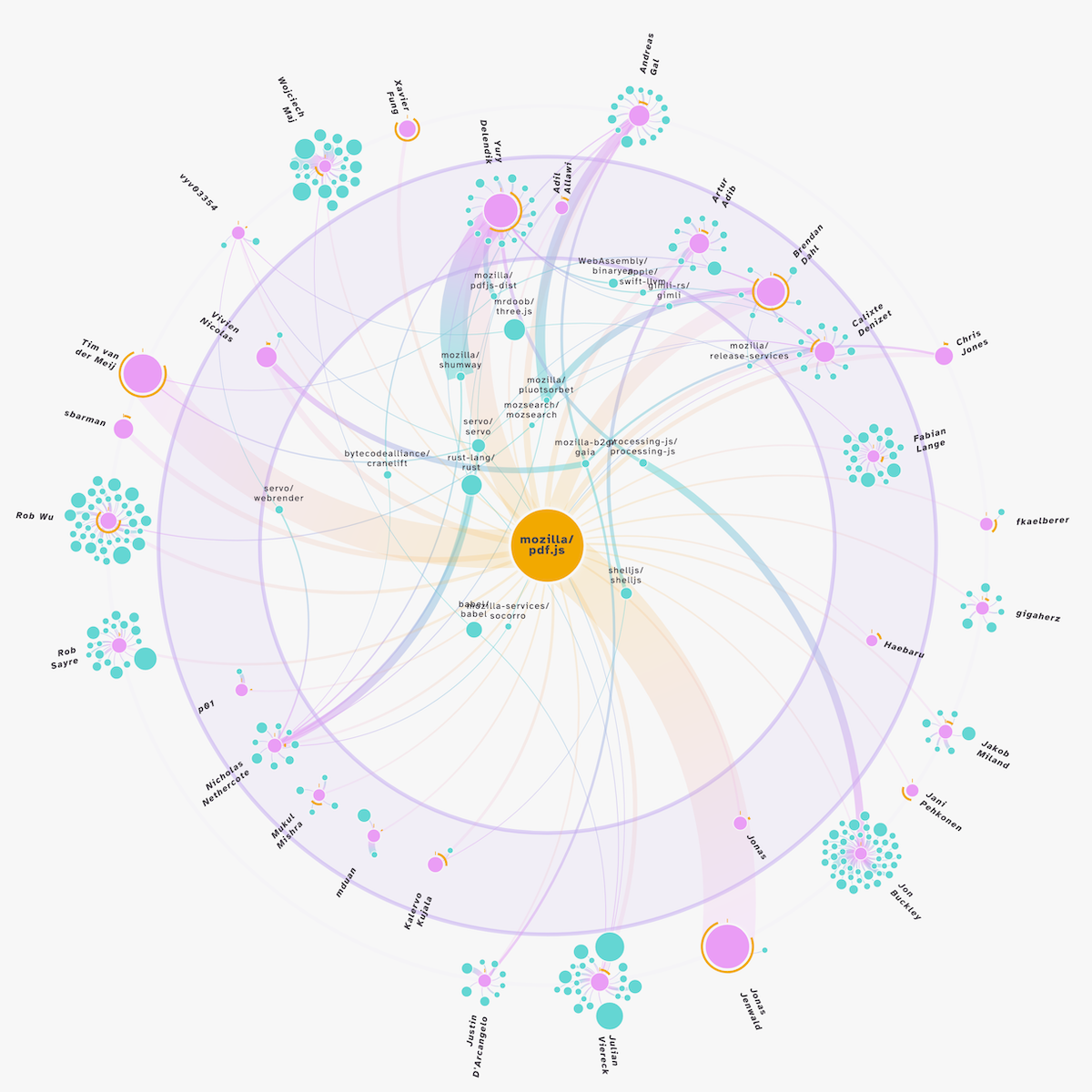
During one of our calls, Adam pointed out that he would really want people to see which of these contributors were receiving compensation through ORCA. Especially in case you included more top contributors than just the ORCA ones. I first thought about altering something such as the transparency of the contributors; more transparent for the non-ORCA ones. However, that wasn’t quite clear enough. After some consideration, I decided to split the one circle along which every contributor was placed into two. An inner circle for the ORCA contributors, and an outer circle for the non-ORCA contributors.
Since there wasn’t any actual ORCA distributed when I was still building this, the visual randomly chose a set of contributors on each refresh.
Some tweaking later, and this is how it looked:
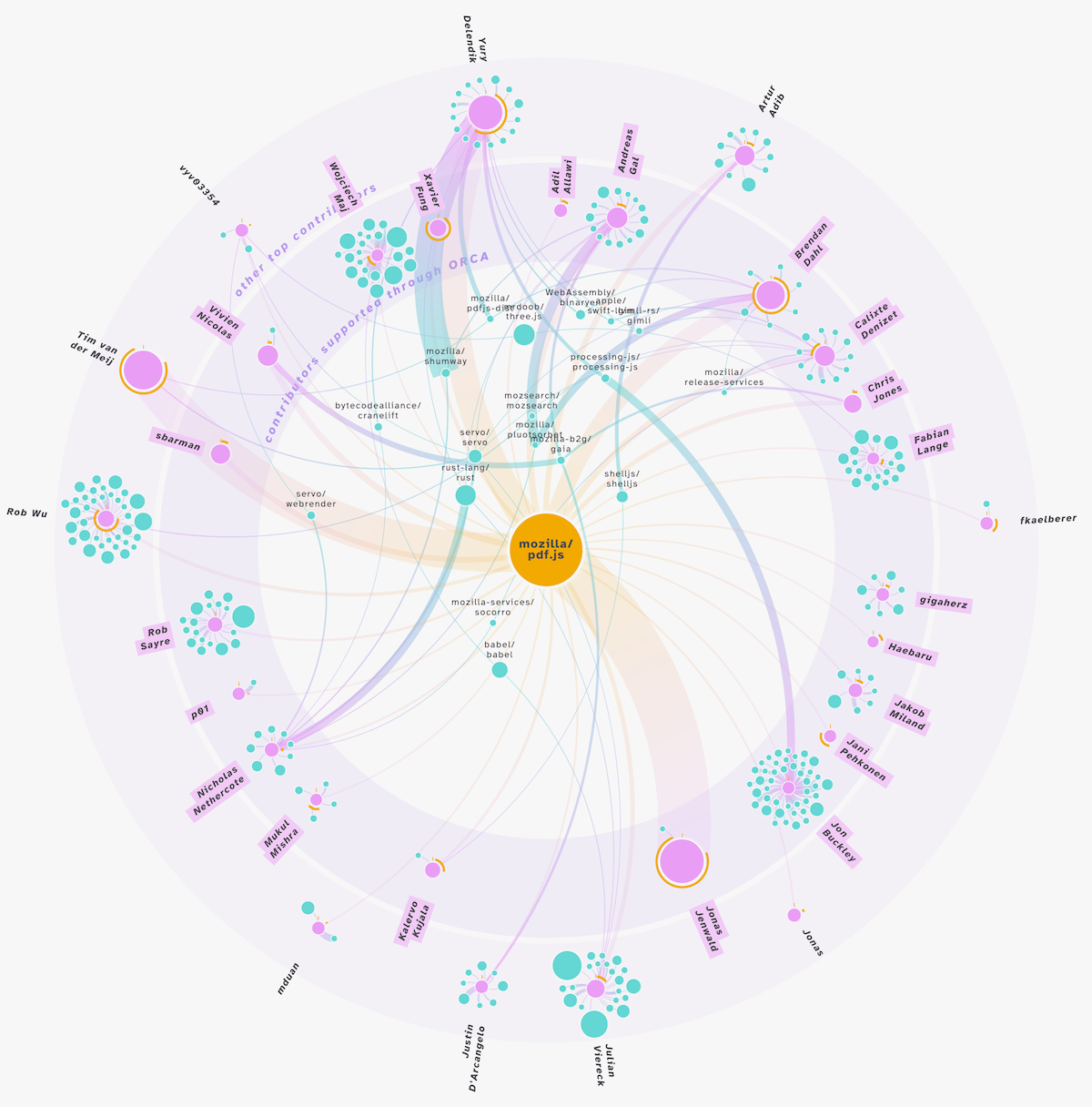
Since I also had a dataset of all the contributors, not just the top ones, I thought it might be nice to have all the remaining contributors “floating” around the central visual. That particular part/dataset is not required to make the central part work, but it does add some extra context and makes it more visual that the repository is build up from the help of many more people than just these top ones.
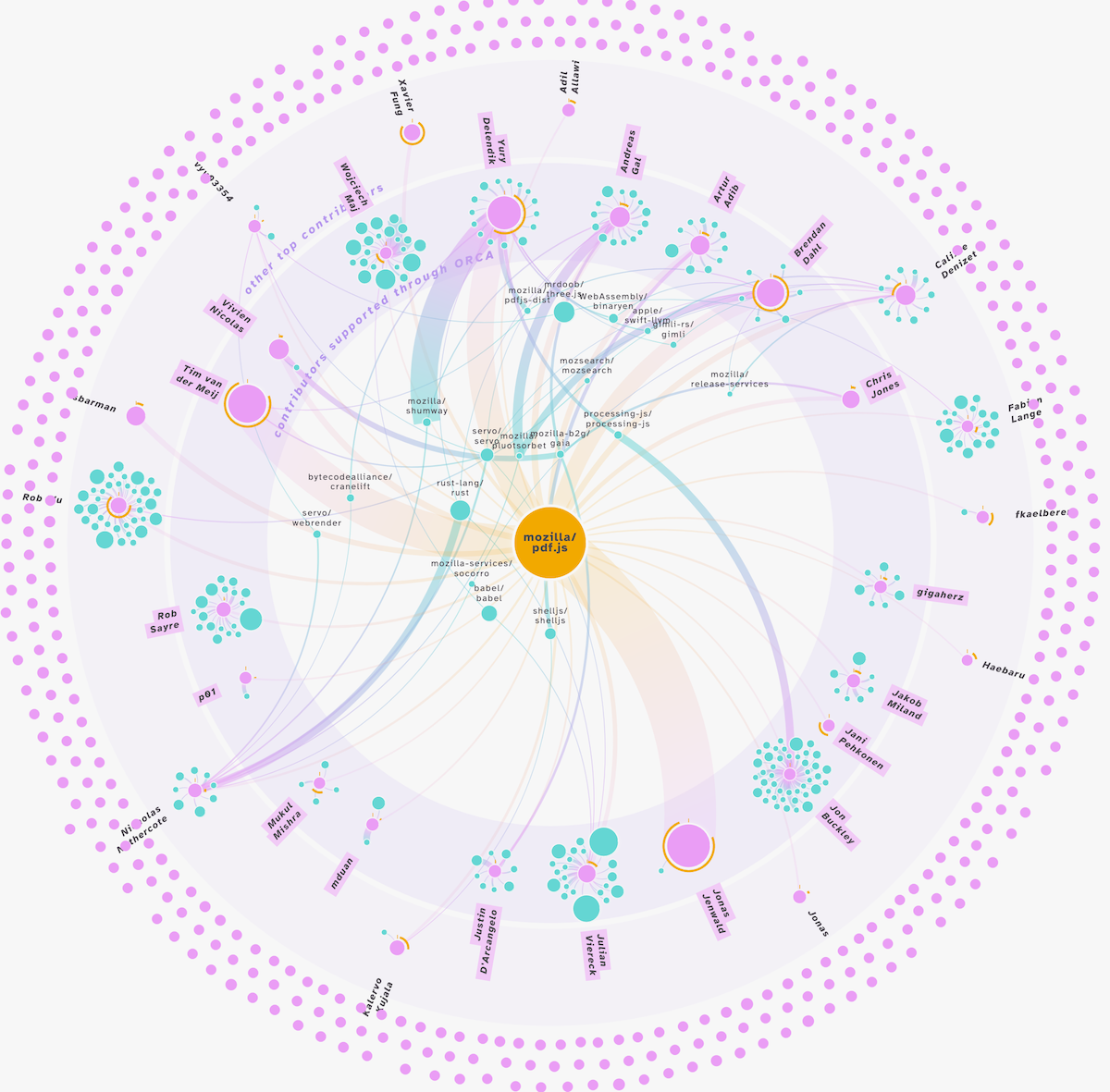
And thus I added a third force algorithm step, where I spread the remaining contributors around the visual (see the image above) and then let them “float” around a bit more, with some more randomness to them.
And Then it All Broke…
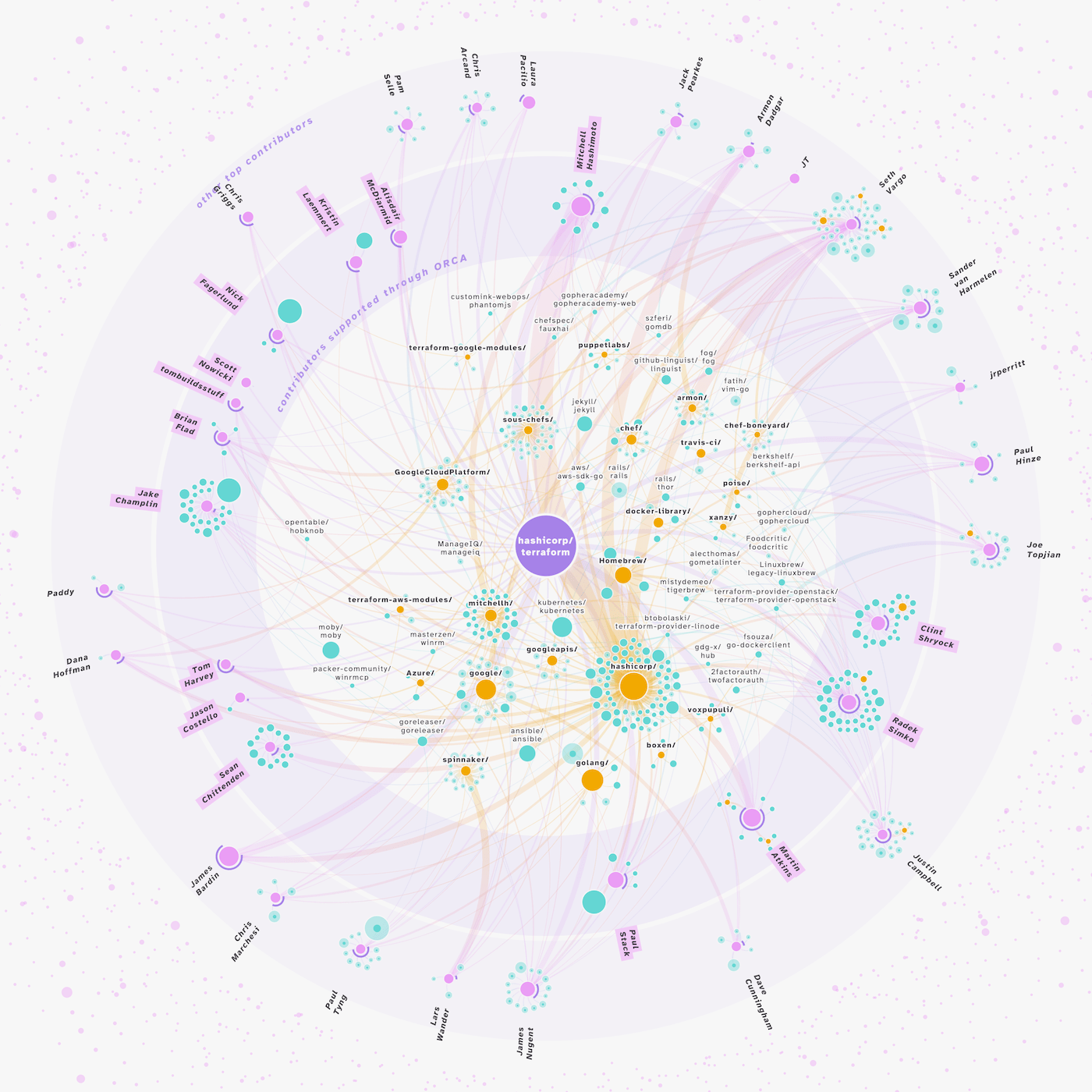
After all that was done, I felt that the visual was basically done. Apart from some more (endless) fine-tuning, and adding the intro, the explanation, the legend (the stuff I always push to the end, because I find it the least fun to do). But then Adam gave me a new repository to work with, Hashicorp’s terraform. A much larger network, with over 2000 contributors (as opposed to pdf.js’ roughly 500).
Even though I selected roughly the same number of people to include (36 people), to be a top contributor to terraform meant that you had to have made a lot more commits to terraform than the top contributors to pdf.js. And it so happens that those people have also done a lot of work on many more other popular repositories. Whereas for pdf.js the visual included 220 repository nodes, the terraform dataset had 590 repositories (with over 30 stars). And my network broke, visually that is…

There were too many repositories that multiple contributors had worked on, and thus were placed in the center. It was quite amazing to see the synergies between these top contributors, so many working on the same repositories and improving them, but my visual couldn’t handle it.
As I showed Adam my mess, he had the brilliant idea to group all of the repositories by the owner, meaning the person or company that owns the GitHub repository (like Hashicorp is the owner of terraform). If you stare at the screenshot above, you might notice the word hashicorp a lot, so grouping by owner definitely seemed to have potential.
It was totally non-trivial to implement though… I didn’t want people to have to supply any other kind of data than simply the contributors, their repositories, and the links between these two. And so grouping by owner, possibly replacing links between a contributor and repository to a contributor and owner (but not more than once!), new links between an owner and repository (only once as well), recalculating line thicknesses (from contributor to owner), which owners were only connected to one contributor (and thus should not be placed in the center, but in the contributor’s single-degree “cloud”), etc. etc, had to be done within the code. In short, it took some time.
Although not complete, once my code was in working order again to at least make a semblance of the network, I couldn’t wait to see the result:

I had made the “owner” circles yellow, wanting to make them stand out from the blue repository circles.
There was still a lot wrong (multiple lines from one contributor to one owner, the owner circles do not yet have their repositories around them, etc.), but it seemed like this might actually work once I had everything in order.
Steadily fixing ever more small things…
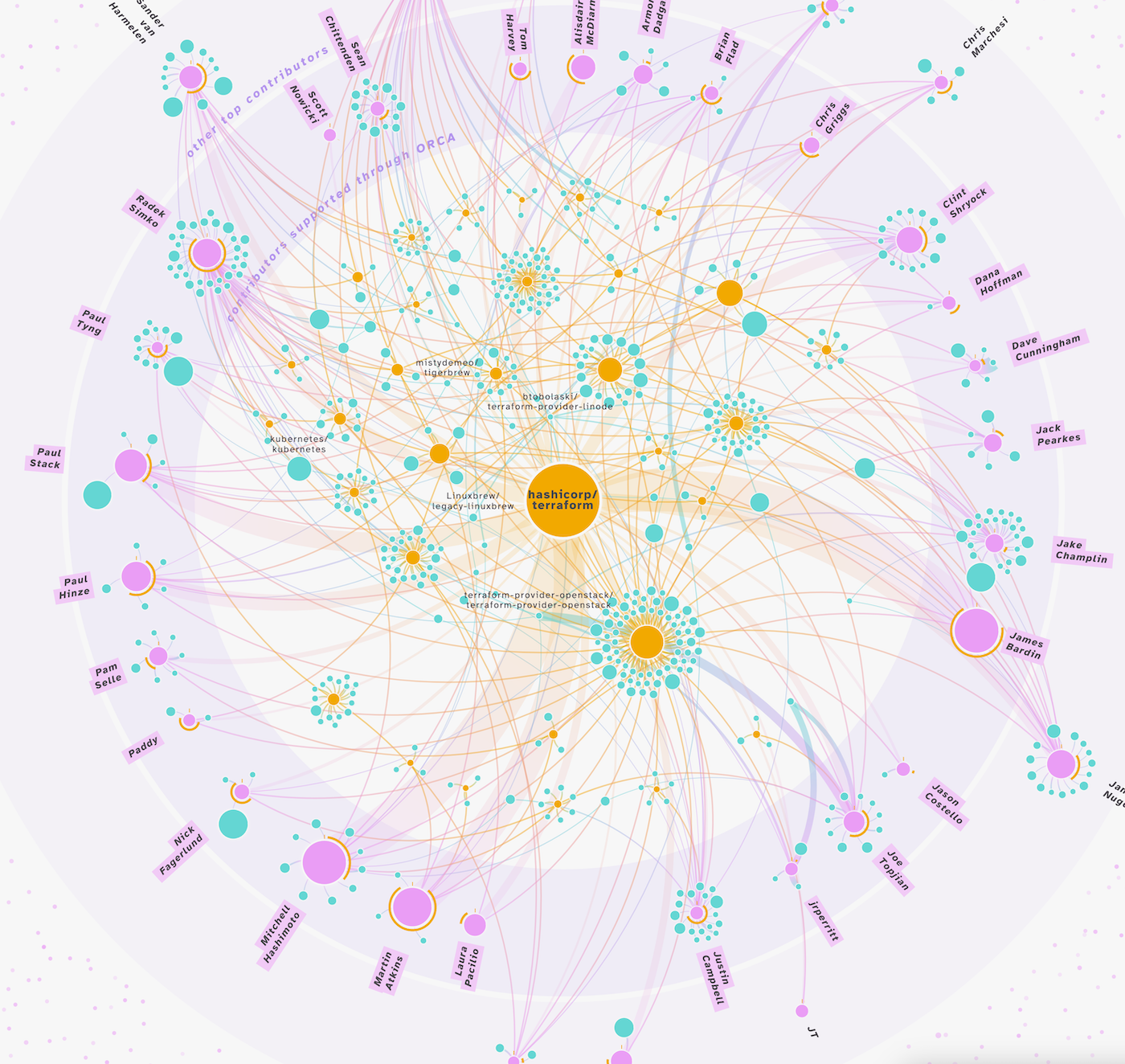
And once I finally had everything working the way I intended, the network was looking much, much better than my first reload with the terraform dataset.

In our next call I showed Adam the updated network for terraform. We tried one more tiny, but eventually fundamental change during the call: sorting the contributors not by name, but by date of first commit. Starting from the top and going clockwise. After seeing the result, Adam, who knows about the history of terraform (he’s quite well versed in everything really) could see the story of this repository in the network. He could go clockwise inside the center and see the story of Hashicorp, and terraform through the other repositories there. He explained how, starting from the top-right-ish, that puppetlabs was a progenitor to terraform, that chef was […] etc.
I was thrilled to hear this, especially when he could then also tell me the story of pdf.js by looking at its network. Sure, you had to know some backstory of these repositories to see these stories. However, since we hoped that those who wanted to apply this visual to a/their repository would know a bit of backstory, and thus be able to see the story for themselves. Even if you didn’t know anything about the repository, as I did for terraform, I could still see the synergies throughout this network, see that these 30+ people worked on so many other open source projects.
Some Leftover Fine-Tuning
I finally took the time to fix the label-overlap. I don’t know if it’s still the best way these days, since it’s been out for years already, but I generally use Elijah Meeks’ d3-bboxCollide plugin for the force algorithm when I need to handle overlapping labels, that can work with rectangles.
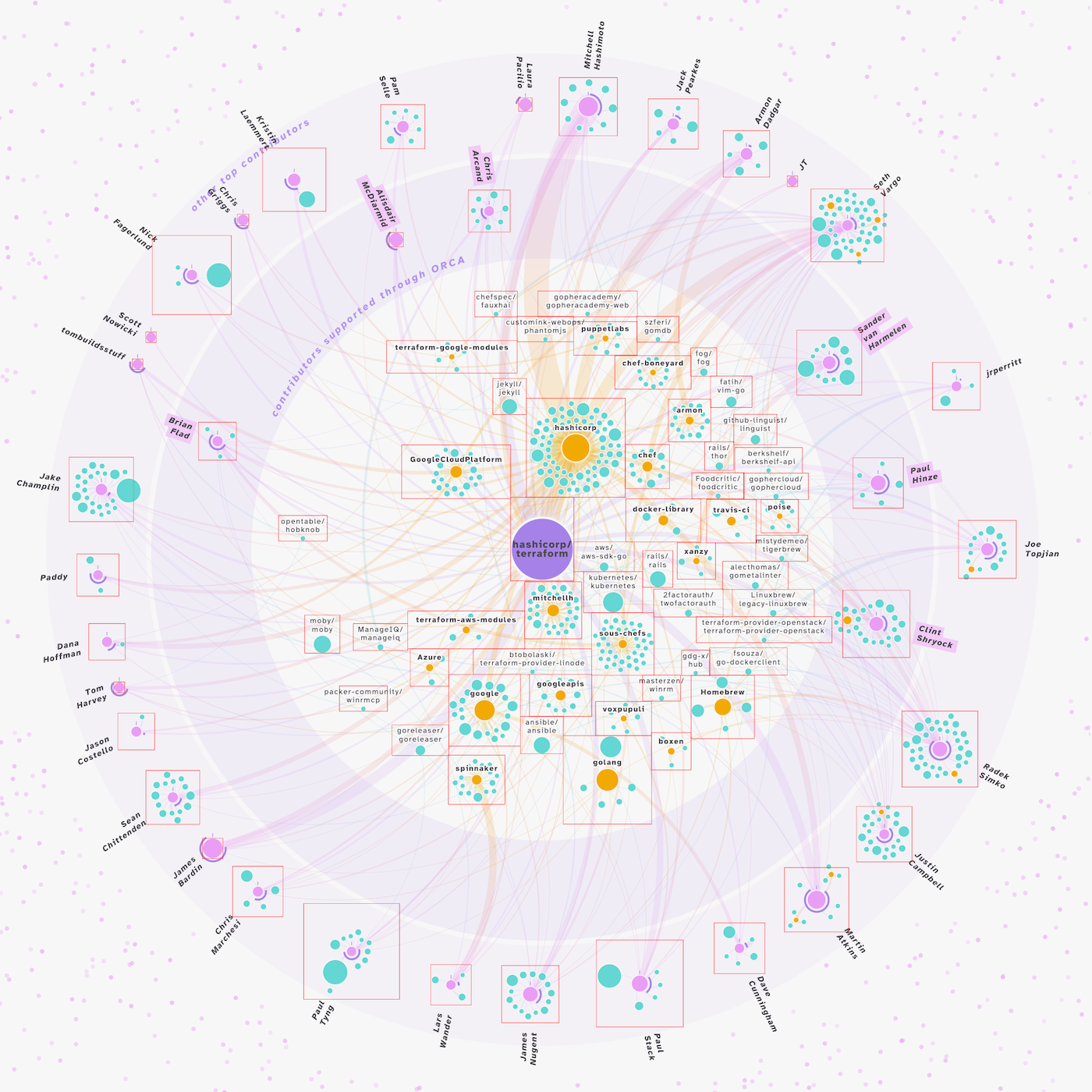
It’s quite full with boxes along the right side of the network, but Adam mentioned that he thought that terraform was probably one of the biggest networks. So fingers crossed that the current visual will be able to handle most other repositories.
It never ceases to amaze me how much time I spend in the finer details. I feel that it usually costs me about 30% to get the overall visual design in place, and then 70% to fine-tune it. Where you can’t really see the visual impact unless you know what you’re looking for (however, those tiny changes definitely have an impact).
For example, the label of the central repository is the only one that is drawn within the circle. I’d made it white by now (looked better than the black). But! What if the name is longer than the size of the purple circle? And so I had to incorporate some code that would also draw legible text outside the purple circle (using double drawing and masking).

I don’t mean to imply that “the other stuff” isn’t important, it is! Very! But I personally don’t enjoy working on the textual side, or legends…
With the visual now finally, truly finally ready this time, I couldn’t postpone the “other stuff” anymore. And so I finally added the introduction, the legend, the explanation, the layout. Incorporating some of the data into the text, which then updates depending on what dataset you supply to the visual, such as the total number of commits, contributors, creation date of the central repository, etc.

The little pink-grey stacked bar chart that shows the division of all commits between the types of contributors is simply three divs using css-grid to define the scale between them, with a html list below it for the legend. I thought that was particularly smart, instead of fiddling around with an svg, haha.
Wrapping Up
It’s not a visual that you can truly understand in a few seconds. However, my hope is that it will provide an insight into the contributors of any GitHub repository that people have never been able to see like this. And that this makes it worth the time it takes to learn how to read the visual.
You can find the interactive visual here and the code and documentation for it here. I’ve tried to add plenty of comments, and if anyone wants to take this visual and run with it, add more metadata, add more interactivity, make it work with even larger datasets, then please go ahead!
And/or if you create a version of the visual with another dataset, I’d love to see it! (feel free to add me to any social media post with the image or email it).
One small warning though, you might need to figure out a way to gather the correct dataset of contributors and the other repositories they worked on, as the method Adam and I used involved Google’s BiqQuery dataset of GitHub and it’s quite outdated by now.